Reference
Data structures
Segment
- class pyannote.core.Segment(start: float = 0.0, end: float = 0.0)[source]
Time interval
- Parameters:
start (float) – interval start time, in seconds.
end (float) – interval end time, in seconds.
Segments can be compared and sorted using the standard operators:
>>> Segment(0, 1) == Segment(0, 1.) True >>> Segment(0, 1) != Segment(3, 4) True >>> Segment(0, 1) < Segment(2, 3) True >>> Segment(0, 1) < Segment(0, 2) True >>> Segment(1, 2) < Segment(0, 3) False
Note
A segment is smaller than another segment if one of these two conditions is verified:
segment.start < other_segment.start
segment.start == other_segment.start and segment.end < other_segment.end
- __and__(other)[source]
Intersection
>>> segment = Segment(0, 10) >>> other_segment = Segment(5, 15) >>> segment & other_segment <Segment(5, 10)>
Note
When the intersection is empty, an empty segment is returned:
>>> segment = Segment(0, 10) >>> other_segment = Segment(15, 20) >>> intersection = segment & other_segment >>> if not intersection: ... # intersection is empty.
- __bool__()[source]
Emptiness
>>> if segment: ... # segment is not empty. ... else: ... # segment is empty.
Note
A segment is considered empty if its end time is smaller than its start time, or its duration is smaller than 1μs.
- __contains__(other: Segment)[source]
Inclusion
>>> segment = Segment(start=0, end=10) >>> Segment(start=3, end=10) in segment: True >>> Segment(start=5, end=15) in segment: False
- __delattr__(name)
Implement delattr(self, name).
- __eq__(other)
Return self==value.
- __ge__(other)
Return self>=value.
- __gt__(other)
Return self>value.
- __hash__()
Return hash(self).
- __init__(start: float = 0.0, end: float = 0.0) None
- __iter__() Iterator[float][source]
Unpack segment boundaries >>> segment = Segment(start, end) >>> start, end = segment
- __le__(other)
Return self<=value.
- __lt__(other)
Return self<value.
- __or__(other: Segment) Segment[source]
Union
>>> segment = Segment(0, 10) >>> other_segment = Segment(5, 15) >>> segment | other_segment <Segment(0, 15)>
Note
When a gap exists between the segment, their union covers the gap as well:
>>> segment = Segment(0, 10) >>> other_segment = Segment(15, 20) >>> segment | other_segment <Segment(0, 20)
- __repr__()[source]
Computer-readable representation
>>> Segment(1337, 1337 + 0.42) <Segment(1337, 1337.42)>
- __setattr__(name, value)
Implement setattr(self, name, value).
- __str__()[source]
Human-readable representation
>>> print(Segment(1337, 1337 + 0.42)) [ 00:22:17.000 --> 00:22:17.420]
Note
Empty segments are printed as “[]”
- __weakref__
list of weak references to the object (if defined)
- __xor__(other: Segment) Segment[source]
Gap
>>> segment = Segment(0, 10) >>> other_segment = Segment(15, 20) >>> segment ^ other_segment <Segment(10, 15)
Note
The gap between a segment and an empty segment is not defined.
>>> segment = Segment(0, 10) >>> empty_segment = Segment(11, 11) >>> segment ^ empty_segment ValueError: The gap between a segment and an empty segment is not defined.
- property duration: float
Segment duration (read-only)
- intersects(other: Segment) bool[source]
Check whether two segments intersect each other
- Parameters:
other (Segment) – Other segment
- Returns:
intersect – True if segments intersect, False otherwise
- Return type:
bool
- property middle: float
Segment mid-time (read-only)
- overlaps(t: float) bool[source]
Check if segment overlaps a given time
- Parameters:
t (float) – Time, in seconds.
- Returns:
overlap – True if segment overlaps time t, False otherwise.
- Return type:
bool
- static set_precision(ndigits: int | None = None)[source]
Automatically round start and end timestamps to ndigits precision after the decimal point
To ensure consistency between Segment instances, it is recommended to call this method only once, right after importing pyannote.core.Segment.
Usage
>>> from pyannote.core import Segment >>> Segment.set_precision(2) >>> Segment(1/3, 2/3) <Segment(0.33, 0.67)>
Timeline
- class pyannote.core.Timeline(segments: Iterable[Segment] | None = None, uri: str | None = None)[source]
Ordered set of segments.
A timeline can be seen as an ordered set of non-empty segments (Segment). Segments can overlap – though adding an already exisiting segment to a timeline does nothing.
- Parameters:
segments (Segment iterator, optional) – initial set of (non-empty) segments
uri (string, optional) – name of segmented resource
- Returns:
timeline – New timeline
- Return type:
- __bool__()[source]
Emptiness
>>> if timeline: ... # timeline is not empty ... else: ... # timeline is empty
- __contains__(included: Segment | Timeline)[source]
Inclusion
Check whether every segment of included does exist in timeline.
- Parameters:
included (Segment or Timeline) – Segment or timeline being checked for inclusion
- Returns:
contains – True if every segment in included exists in timeline, False otherwise
- Return type:
bool
Examples
>>> timeline1 = Timeline(segments=[Segment(0, 10), Segment(1, 13.37)]) >>> timeline2 = Timeline(segments=[Segment(0, 10)]) >>> timeline1 in timeline2 False >>> timeline2 in timeline1 >>> Segment(1, 13.37) in timeline1 True
- __eq__(other: Timeline)[source]
Equality
Two timelines are equal if and only if their segments are equal.
>>> timeline1 = Timeline([Segment(0, 1), Segment(2, 3)]) >>> timeline2 = Timeline([Segment(2, 3), Segment(0, 1)]) >>> timeline3 = Timeline([Segment(2, 3)]) >>> timeline1 == timeline2 True >>> timeline1 == timeline3 False
- __getitem__(k: int) Segment[source]
Get segment by index (in chronological order)
>>> first_segment = timeline[0] >>> penultimate_segment = timeline[-2]
- __hash__ = None
- __iter__() Iterator[Segment][source]
Iterate over segments (in chronological order)
>>> for segment in timeline: ... # do something with the segment
See also
- __repr__()[source]
Computer-readable representation
>>> Timeline(segments=[Segment(0, 10), Segment(1, 13.37)]) <Timeline(uri=None, segments=[<Segment(0, 10)>, <Segment(1, 13.37)>])>
- __str__()[source]
Human-readable representation
>>> timeline = Timeline(segments=[Segment(0, 10), Segment(1, 13.37)]) >>> print(timeline) [[ 00:00:00.000 --> 00:00:10.000] [ 00:00:01.000 --> 00:00:13.370]]
- __weakref__
list of weak references to the object (if defined)
- add(segment: Segment) Timeline[source]
Add a segment (in place)
- Parameters:
segment (Segment) – Segment that is being added
- Returns:
self – Updated timeline.
- Return type:
Note
If the timeline already contains this segment, it will not be added again, as a timeline is meant to be a set of segments (not a list).
If the segment is empty, it will not be added either, as a timeline only contains non-empty segments.
- co_iter(other: Timeline) Iterator[Tuple[Segment, Segment]][source]
Iterate over pairs of intersecting segments
>>> timeline1 = Timeline([Segment(0, 2), Segment(1, 2), Segment(3, 4)]) >>> timeline2 = Timeline([Segment(1, 3), Segment(3, 5)]) >>> for segment1, segment2 in timeline1.co_iter(timeline2): ... print(segment1, segment2) (<Segment(0, 2)>, <Segment(1, 3)>) (<Segment(1, 2)>, <Segment(1, 3)>) (<Segment(3, 4)>, <Segment(3, 5)>)
- copy(segment_func: Callable[[Segment], Segment] | None = None) Timeline[source]
Get a copy of the timeline
If segment_func is provided, it is applied to each segment first.
- Parameters:
segment_func (callable, optional) – Callable that takes a segment as input, and returns a segment. Defaults to identity function (segment_func(segment) = segment)
- Returns:
timeline – Copy of the timeline
- Return type:
- covers(other: Timeline) bool[source]
Check whether other timeline is fully covered by the timeline
Parameter
- otherTimeline
Second timeline
- returns:
covers – True if timeline covers “other” timeline entirely. False if at least one segment of “other” is not fully covered by timeline
- rtype:
bool
- crop(support: Segment | Timeline, mode: Literal['intersection', 'loose', 'strict'] = 'intersection', returns_mapping: bool = False) Timeline | Tuple[Timeline, Dict[Segment, Segment]][source]
Crop timeline to new support
- Parameters:
support (Segment or Timeline) – If support is a Timeline, its support is used.
mode ({'strict', 'loose', 'intersection'}, optional) – Controls how segments that are not fully included in support are handled. ‘strict’ mode only keeps fully included segments. ‘loose’ mode keeps any intersecting segment. ‘intersection’ mode keeps any intersecting segment but replace them by their actual intersection.
returns_mapping (bool, optional) – In ‘intersection’ mode, return a dictionary whose keys are segments of the cropped timeline, and values are list of the original segments that were cropped. Defaults to False.
- Returns:
cropped (Timeline) – Cropped timeline
mapping (dict) – When ‘returns_mapping’ is True, dictionary whose keys are segments of ‘cropped’, and values are lists of corresponding original segments.
Examples
>>> timeline = Timeline([Segment(0, 2), Segment(1, 2), Segment(3, 4)]) >>> timeline.crop(Segment(1, 3)) <Timeline(uri=None, segments=[<Segment(1, 2)>])>
>>> timeline.crop(Segment(1, 3), mode='loose') <Timeline(uri=None, segments=[<Segment(0, 2)>, <Segment(1, 2)>])>
>>> timeline.crop(Segment(1, 3), mode='strict') <Timeline(uri=None, segments=[<Segment(1, 2)>])>
>>> cropped, mapping = timeline.crop(Segment(1, 3), returns_mapping=True) >>> print(mapping) {<Segment(1, 2)>: [<Segment(0, 2)>, <Segment(1, 2)>]}
- crop_iter(support: Segment | Timeline, mode: Literal['intersection', 'loose', 'strict'] = 'intersection', returns_mapping: bool = False) Iterator[Tuple[Segment, Segment] | Segment][source]
Like crop but returns a segment iterator instead
See also
- duration() float[source]
Timeline duration
The timeline duration is the sum of the durations of the segments in the timeline support.
- Returns:
duration – Duration of timeline support, in seconds.
- Return type:
float
- empty() Timeline[source]
Return an empty copy
- Returns:
empty – Empty timeline using the same ‘uri’ attribute.
- Return type:
- extent() Segment[source]
Extent
The extent of a timeline is the segment of minimum duration that contains every segments of the timeline. It is unique, by definition. The extent of an empty timeline is an empty segment.
A picture is worth a thousand words:
timeline |------| |------| |----| |--| |-----| |----------| timeline.extent() |--------------------------------|
- Returns:
extent – Timeline extent
- Return type:
Examples
>>> timeline = Timeline(segments=[Segment(0, 1), Segment(9, 10)]) >>> timeline.extent() <Segment(0, 10)>
- extrude(removed: Segment | Timeline, mode: Literal['intersection', 'loose', 'strict'] = 'intersection') Timeline[source]
Remove segments that overlap removed support.
- Parameters:
removed (Segment or Timeline) – If support is a Timeline, its support is used.
mode ({'strict', 'loose', 'intersection'}, optional) – Controls how segments that are not fully included in removed are handled. ‘strict’ mode only removes fully included segments. ‘loose’ mode removes any intersecting segment. ‘intersection’ mode removes the overlapping part of any intersecting segment.
- Returns:
extruded – Extruded timeline
- Return type:
Examples
>>> timeline = Timeline([Segment(0, 2), Segment(1, 2), Segment(3, 5)]) >>> timeline.extrude(Segment(1, 2)) <Timeline(uri=None, segments=[<Segment(0, 1)>, <Segment(3, 5)>])>
>>> timeline.extrude(Segment(1, 3), mode='loose') <Timeline(uri=None, segments=[<Segment(3, 5)>])>
>>> timeline.extrude(Segment(1, 3), mode='strict') <Timeline(uri=None, segments=[<Segment(0, 2)>, <Segment(3, 5)>])>
- gaps(support: Segment | Timeline | None = None) Timeline[source]
Gaps
A picture is worth a thousand words:
timeline |------| |------| |----| |--| |-----| |----------| timeline.gaps() |--| |--|
- Parameters:
support (None, Segment or Timeline) – Support in which gaps are looked for. Defaults to timeline extent
- Returns:
gaps – Timeline made of all gaps from original timeline, and delimited by provided support
- Return type:
See also
- gaps_iter(support: Segment | Timeline | None = None) Iterator[Segment][source]
Like gaps but returns a segment generator instead
See also
- get_overlap() Timeline[source]
Get overlapping parts of the timeline.
A simple illustration:
timeline |------| |------| |----| |--| |-----| |----------| timeline.get_overlap() |--| |---| |----|
- Returns:
overlap – Timeline of the overlaps.
- Return type:
pyannote.core.Timeline
- index(segment: Segment) int[source]
Get index of (existing) segment
- Parameters:
segment (Segment) – Segment that is being looked for.
- Returns:
position – Index of segment in timeline
- Return type:
int
- Raises:
ValueError if segment is not present. –
- overlapping(t: float) List[Segment][source]
Get list of segments overlapping t
- Parameters:
t (float) – Timestamp, in seconds.
- Returns:
segments – List of all segments of timeline containing time t
- Return type:
list
- overlapping_iter(t: float) Iterator[Segment][source]
Like overlapping but returns a segment iterator instead
See also
- remove(segment: Segment) Timeline[source]
Remove a segment (in place)
- Parameters:
segment (Segment) – Segment that is being removed
- Returns:
self – Updated timeline.
- Return type:
Note
If the timeline does not contain this segment, this does nothing
- segmentation() Timeline[source]
Segmentation
Create the unique timeline with same support and same set of segment boundaries as original timeline, but with no overlapping segments.
A picture is worth a thousand words:
timeline |------| |------| |----| |--| |-----| |----------| timeline.segmentation() |-|--|-| |-|---|--| |--|----|--|
- Returns:
timeline – (unique) timeline with same support and same set of segment boundaries as original timeline, but with no overlapping segments.
- Return type:
- support(collar: float = 0.0) Timeline[source]
Timeline support
The support of a timeline is the timeline with the minimum number of segments with exactly the same time span as the original timeline. It is (by definition) unique and does not contain any overlapping segments.
A picture is worth a thousand words:
collar |---| timeline |------| |------| |----| |--| |-----| |----------| timeline.support() |------| |--------| |----------| timeline.support(collar) |------------------| |----------|
- Parameters:
collar (float, optional) – Merge separated by less than collar seconds. This is why there are only two segments in the final timeline in the above figure. Defaults to 0.
- Returns:
support – Timeline support
- Return type:
- support_iter(collar: float = 0.0) Iterator[Segment][source]
Like support but returns a segment generator instead
See also
- to_annotation(generator: str | Iterable[Hashable] | None = 'string', modality: str | None = None) Annotation[source]
Turn timeline into an annotation
Each segment is labeled by a unique label.
- Parameters:
generator ('string', 'int', or iterable, optional) – If ‘string’ (default) generate string labels. If ‘int’, generate integer labels. If iterable, use it to generate labels.
modality (str, optional)
- Returns:
annotation – Annotation
- Return type:
- to_uem() str[source]
Serialize timeline as a string using UEM format
- Returns:
serialized – UEM string
- Return type:
str
- union(timeline: Timeline) Timeline[source]
Create new timeline made of union of segments
- Parameters:
timeline (Timeline) – Timeline whose segments are being added
- Returns:
union – New timeline containing the union of both timelines.
- Return type:
Note
This does the same as timeline.update(…) except it returns a new timeline, and the original one is not modified.
- update(timeline: Segment) Timeline[source]
Add every segments of an existing timeline (in place)
- Parameters:
timeline (Timeline) – Timeline whose segments are being added
- Returns:
self – Updated timeline
- Return type:
Note
Only segments that do not already exist will be added, as a timeline is meant to be a set of segments (not a list).
Annotation
- class pyannote.core.Annotation(uri: str | None = None, modality: str | None = None)[source]
- Parameters:
uri (string, optional) – name of annotated resource (e.g. audio or video file)
modality (string, optional) – name of annotated modality
- Returns:
annotation – New annotation
- Return type:
- __bool__()[source]
Emptiness
>>> if annotation: ... # annotation is not empty ... else: ... # annotation is empty
- __contains__(included: Segment | Timeline)[source]
Inclusion
Check whether every segment of included does exist in annotation.
- __delitem__(key: Segment | Tuple[Segment, str | int])[source]
Delete one track
>>> del annotation[segment, track]
Delete all tracks of a segment
>>> del annotation[segment]
- __eq__(other: Annotation)[source]
Equality
>>> annotation == other
Two annotations are equal if and only if their tracks and associated labels are equal.
- __getitem__(key: Segment | Tuple[Segment, str | int]) Hashable[source]
Get track label
>>> label = annotation[segment, track]
Note
annotation[segment]is equivalent toannotation[segment, '_']
- __hash__ = None
- __iter__() Iterator[Tuple[Segment, Hashable]][source]
Iterate over (segment, label) pairs in chronological order
Examples
>>> for segment, label in annotation: ... # do something with the segment and its label
- __mul__(other: Annotation) ndarray[source]
Cooccurrence (or confusion) matrix
>>> matrix = annotation * other
- Parameters:
other (Annotation) – Second annotation
- Returns:
cooccurrence – Cooccurrence matrix where n_self (resp. n_other) is the number of labels in self (resp. other).
- Return type:
(n_self, n_other) np.ndarray
- __ne__(other: Annotation)[source]
Inequality
- __setitem__(key: Segment | Tuple[Segment, str | int], label: Hashable)[source]
Add new or update existing track
>>> annotation[segment, track] = label
If (segment, track) does not exist, it is added. If (segment, track) already exists, it is updated.
Note
annotation[segment] = labelis equivalent toannotation[segment, '_'] = labelNote
If segment is empty, it does nothing.
- __weakref__
list of weak references to the object (if defined)
- argmax(support: Segment | Timeline | None = None) Hashable | None[source]
Get label with longest duration
- Parameters:
support (Segment or Timeline, optional) – Find label with longest duration within provided support. Defaults to whole extent.
- Returns:
label – Label with longest intersection
- Return type:
any existing label or None
Examples
>>> annotation = Annotation(modality='speaker') >>> annotation[Segment(0, 10), 'speaker1'] = 'Alice' >>> annotation[Segment(8, 20), 'speaker1'] = 'Bob' >>> print "%s is such a talker!" % annotation.argmax() Bob is such a talker! >>> segment = Segment(22, 23) >>> if not annotation.argmax(support): ... print "No label intersecting %s" % segment No label intersection [22 --> 23]
- chart(percent: bool = False) List[Tuple[Hashable, float]][source]
Get labels chart (from longest to shortest duration)
- Parameters:
percent (bool, optional) – Return list of (label, percentage) tuples. Defaults to returning list of (label, duration) tuples.
- Returns:
chart – List of (label, duration), sorted by duration in decreasing order.
- Return type:
list
- co_iter(other: Annotation) Iterator[Tuple[Tuple[Segment, str | int], Tuple[Segment, str | int]]][source]
Iterate over pairs of intersecting tracks
- Parameters:
other (Annotation) – Second annotation
- Returns:
iterable – Yields pairs of intersecting tracks, in chronological (then alphabetical) order.
- Return type:
See also
- copy() Annotation[source]
Get a copy of the annotation
- Returns:
annotation – Copy of the annotation
- Return type:
- crop(support: Segment | Timeline, mode: Literal['intersection', 'loose', 'strict'] = 'intersection') Annotation[source]
Crop annotation to new support
- Parameters:
support (Segment or Timeline) – If support is a Timeline, its support is used.
mode ({'strict', 'loose', 'intersection'}, optional) – Controls how segments that are not fully included in support are handled. ‘strict’ mode only keeps fully included segments. ‘loose’ mode keeps any intersecting segment. ‘intersection’ mode keeps any intersecting segment but replace them by their actual intersection.
- Returns:
cropped – Cropped annotation
- Return type:
Note
In ‘intersection’ mode, the best is done to keep the track names unchanged. However, in some cases where two original segments are cropped into the same resulting segments, conflicting track names are modified to make sure no track is lost.
- discretize(support: Segment | None = None, resolution: float | SlidingWindow = 0.01, labels: List[Hashable] | None = None, duration: float | None = None)[source]
Discretize
- Parameters:
support (Segment, optional) – Part of annotation to discretize. Defaults to annotation full extent.
resolution (float or SlidingWindow, optional) – Defaults to 10ms frames.
labels (list of labels, optional) – Defaults to self.labels()
duration (float, optional) – Overrides support duration and ensures that the number of returned frames is fixed (which might otherwise not be the case because of rounding errors).
- Returns:
discretized – (num_frames, num_labels)-shaped binary features.
- Return type:
- empty() Annotation[source]
Return an empty copy
- Returns:
empty – Empty annotation using the same ‘uri’ and ‘modality’ attributes.
- Return type:
- extrude(removed: Segment | Timeline, mode: Literal['intersection', 'loose', 'strict'] = 'intersection') Annotation[source]
Remove segments that overlap removed support.
A simple illustration:
A |------| |------| # B |----------| # self C |--------------| |------| # # |-------| |-----------| # removed # A # B |---| # mode="intersection" C |--| |------| # A # B # mode="loose" C |------| # A |------| # B |----------| # mode="strict" C |--------------| |------| #- Parameters:
removed (Segment or Timeline) – If support is a Timeline, its support is used.
mode ({'strict', 'loose', 'intersection'}, optional) – Controls how segments that are not fully included in removed are handled. ‘strict’ mode only removes fully included segments. ‘loose’ mode removes any intersecting segment. ‘intersection’ mode removes the overlapping part of any intersecting segment.
- Returns:
extruded – Extruded annotation
- Return type:
Note
In ‘intersection’ mode, the best is done to keep the track names unchanged. However, in some cases where two original segments are cropped into the same resulting segments, conflicting track names are modified to make sure no track is lost.
- classmethod from_records(records: Iterator[Tuple[Segment, str | int, Hashable]], uri: str | None = None, modality: str | None = None) Annotation[source]
Annotation
- Parameters:
records (iterator of tuples) – (segment, track, label) tuples
uri (string, optional) – name of annotated resource (e.g. audio or video file)
modality (string, optional) – name of annotated modality
- Returns:
annotation – New annotation
- Return type:
- get_labels(segment: Segment, unique: bool = True) Set[Hashable] | List[Hashable][source]
Query labels by segment
- Parameters:
segment (Segment) – Query
unique (bool, optional) – When False, return the list of (possibly repeated) labels. Defaults to returning the set of labels.
- Returns:
labels – Set (resp. list) of labels for segment if it exists, empty set (resp. list) otherwise if unique (resp. if not unique).
- Return type:
set or list
Examples
>>> annotation = Annotation() >>> segment = Segment(0, 2) >>> annotation[segment, 'speaker1'] = 'Bernard' >>> annotation[segment, 'speaker2'] = 'John' >>> print sorted(annotation.get_labels(segment)) set(['Bernard', 'John']) >>> print annotation.get_labels(Segment(1, 2)) set([])
- get_overlap(labels: Iterable[Hashable] | None = None) Timeline[source]
Get overlapping parts of the annotation.
A simple illustration:
annotation A |------| |------| |----| B |--| |-----| |----------| C |--------------| |------| annotation.get_overlap() |------| |-----| |--------| annotation.get_overlap(for_labels=["A", "B"]) |--| |--| |----|
- Parameters:
labels (optional list of labels) – Labels for which to consider the overlap
- Returns:
overlap – Timeline of the overlaps.
- Return type:
pyannote.core.Timeline
- get_timeline(copy: bool = True) Timeline[source]
Get timeline made of all annotated segments
- Parameters:
copy (bool, optional) – Defaults (True) to returning a copy of the internal timeline. Set to False to return the actual internal timeline (faster).
- Returns:
timeline – Timeline made of all annotated segments.
- Return type:
Note
In case copy is set to False, be careful not to modify the returned timeline, as it may lead to weird subsequent behavior of the annotation instance.
- get_tracks(segment: Segment) Set[str | int][source]
Query tracks by segment
- Parameters:
segment (Segment) – Query
- Returns:
tracks – Set of tracks
- Return type:
set
Note
This will return an empty set if segment does not exist.
- has_track(segment: Segment, track: str | int) bool[source]
Check whether a given track exists
- Parameters:
segment (Segment) – Query segment
track – Query track
- Returns:
exists – True if track exists for segment
- Return type:
bool
- itersegments()[source]
Iterate over segments (in chronological order)
>>> for segment in annotation.itersegments(): ... # do something with the segment
See also
- itertracks(yield_label: bool = False) Iterator[Tuple[Segment, str | int] | Tuple[Segment, str | int, Hashable]][source]
Iterate over tracks (in chronological order)
- Parameters:
yield_label (bool, optional) – When True, yield (segment, track, label) tuples, such that annotation[segment, track] == label. Defaults to yielding (segment, track) tuple.
Examples
>>> for segment, track in annotation.itertracks(): ... # do something with the track
>>> for segment, track, label in annotation.itertracks(yield_label=True): ... # do something with the track and its label
- label_duration(label: Hashable) float[source]
Label duration
Equivalent to
Annotation.label_timeline(label).duration()- Parameters:
label (object) – Query
- Returns:
duration – Duration, in seconds.
- Return type:
float
See also
- label_support(label: Hashable) Timeline[source]
Label support
Equivalent to
Annotation.label_timeline(label).support()- Parameters:
label (object) – Query
- Returns:
support – Label support
- Return type:
See also
- label_timeline(label: Hashable, copy: bool = True) Timeline[source]
Query segments by label
- Parameters:
label (object) – Query
copy (bool, optional) – Defaults (True) to returning a copy of the internal timeline. Set to False to return the actual internal timeline (faster).
- Returns:
timeline – Timeline made of all segments for which at least one track is annotated as label
- Return type:
Note
If label does not exist, this will return an empty timeline.
Note
In case copy is set to False, be careful not to modify the returned timeline, as it may lead to weird subsequent behavior of the annotation instance.
- labels() List[Hashable][source]
Get sorted list of labels
- Returns:
labels – Sorted list of labels
- Return type:
list
- new_track(segment: Segment, candidate: str | int | None = None, prefix: str | None = None) str | int[source]
Generate a new track name for given segment
Ensures that the returned track name does not already exist for the given segment.
- Parameters:
segment (Segment) – Segment for which a new track name is generated.
candidate (any valid track name, optional) – When provided, try this candidate name first.
prefix (str, optional) – Track name prefix. Defaults to the empty string ‘’.
- Returns:
name – New track name
- Return type:
str
- relabel_tracks(generator: Literal['int', 'string'] | Iterator[Hashable] = 'string') Annotation[source]
Relabel tracks
Create a new annotation where each track has a unique label.
- Parameters:
generator ('string', 'int' or iterable, optional) – If ‘string’ (default) relabel tracks to ‘A’, ‘B’, ‘C’, … If ‘int’ relabel to 0, 1, 2, … If iterable, use it to generate labels.
- Returns:
renamed – New annotation with relabeled tracks.
- Return type:
- rename_labels(mapping: Dict | None = None, generator: Literal['int', 'string'] | Iterator[Hashable] = 'string', copy: bool = True) Annotation[source]
Rename labels
- Parameters:
mapping (dict, optional) – {old_name: new_name} mapping dictionary.
generator ('string', 'int' or iterable, optional) – If ‘string’ (default) rename label to ‘A’, ‘B’, ‘C’, … If ‘int’, rename to 0, 1, 2, etc. If iterable, use it to generate labels.
copy (bool, optional) – Set to True to return a copy of the annotation. Set to False to update the annotation in-place. Defaults to True.
- Returns:
renamed – Annotation where labels have been renamed
- Return type:
Note
Unmapped labels are kept unchanged.
Note
Parameter generator has no effect when mapping is provided.
- rename_tracks(generator: Literal['int', 'string'] | Iterator[Hashable] = 'string') Annotation[source]
Rename all tracks
- Parameters:
generator ('string', 'int', or iterable, optional) – If ‘string’ (default) rename tracks to ‘A’, ‘B’, ‘C’, etc. If ‘int’, rename tracks to 0, 1, 2, etc. If iterable, use it to generate track names.
- Returns:
renamed – Copy of the original annotation where tracks are renamed.
- Return type:
Example
>>> annotation = Annotation() >>> annotation[Segment(0, 1), 'a'] = 'a' >>> annotation[Segment(0, 1), 'b'] = 'b' >>> annotation[Segment(1, 2), 'a'] = 'a' >>> annotation[Segment(1, 3), 'c'] = 'c' >>> print(annotation) [ 00:00:00.000 --> 00:00:01.000] a a [ 00:00:00.000 --> 00:00:01.000] b b [ 00:00:01.000 --> 00:00:02.000] a a [ 00:00:01.000 --> 00:00:03.000] c c >>> print(annotation.rename_tracks(generator='int')) [ 00:00:00.000 --> 00:00:01.000] 0 a [ 00:00:00.000 --> 00:00:01.000] 1 b [ 00:00:01.000 --> 00:00:02.000] 2 a [ 00:00:01.000 --> 00:00:03.000] 3 c
- subset(labels: Iterable[Hashable], invert: bool = False) Annotation[source]
Filter annotation by labels
- Parameters:
labels (iterable) – List of filtered labels
invert (bool, optional) – If invert is True, extract all but requested labels
- Returns:
filtered – Filtered annotation
- Return type:
- support(collar: float = 0.0) Annotation[source]
Annotation support
The support of an annotation is an annotation where contiguous tracks with same label are merged into one unique covering track.
A picture is worth a thousand words:
collar |---| annotation |--A--| |--A--| |-B-| |-B-| |--C--| |----B-----| annotation.support(collar) |------A------| |------B------| |-B-| |--C--|
- Parameters:
collar (float, optional) – Merge tracks with same label and separated by less than collar seconds. This is why ‘A’ tracks are merged in above figure. Defaults to 0.
- Returns:
support – Annotation support
- Return type:
Note
Track names are lost in the process.
- to_lab() str[source]
Serialize annotation as a string using LAB format
- Returns:
serialized – LAB string
- Return type:
str
- to_rttm() str[source]
Serialize annotation as a string using RTTM format
- Returns:
serialized – RTTM string
- Return type:
str
- update(annotation: Annotation, copy: bool = False) Annotation[source]
Add every track of an existing annotation (in place)
- Parameters:
annotation (Annotation) – Annotation whose tracks are being added
copy (bool, optional) – Return a copy of the annotation. Defaults to updating the annotation in-place.
- Returns:
self – Updated annotation
- Return type:
Note
Existing tracks are updated with the new label.
SlidingWindow
- class pyannote.core.SlidingWindow(duration=0.03, step=0.01, start=0.0, end=None)[source]
Sliding window
- Parameters:
duration (float > 0, optional) – Window duration, in seconds. Default is 30 ms.
step (float > 0, optional) – Step between two consecutive position, in seconds. Default is 10 ms.
start (float, optional) – First start position of window, in seconds. Default is 0.
end (float > start, optional) – Default is infinity (ie. window keeps sliding forever)
Examples
>>> sw = SlidingWindow(duration, step, start) >>> frame_range = (a, b) >>> frame_range == sw.toFrameRange(sw.toSegment(*frame_range)) ... True
>>> segment = Segment(A, B) >>> new_segment = sw.toSegment(*sw.toFrameRange(segment)) >>> abs(segment) - abs(segment & new_segment) < .5 * sw.step
>>> sw = SlidingWindow(end=0.1) >>> print(next(sw)) [ 00:00:00.000 --> 00:00:00.030] >>> print(next(sw)) [ 00:00:00.010 --> 00:00:00.040]
- __call__(support: Segment | Timeline, align_last: bool = False) Iterable[Segment][source]
Slide window over support
Parameter
- supportSegment or Timeline
Support on which to slide the window.
- align_lastbool, optional
Yield a final segment so that it aligns exactly with end of support.
- Yields:
chunk (Segment)
Example
>>> window = SlidingWindow(duration=2., step=1.) >>> for chunk in window(Segment(3, 7.5)): ... print(tuple(chunk)) (3.0, 5.0) (4.0, 6.0) (5.0, 7.0) >>> for chunk in window(Segment(3, 7.5), align_last=True): ... print(tuple(chunk)) (3.0, 5.0) (4.0, 6.0) (5.0, 7.0) (5.5, 7.5)
- __getitem__(i: int) Segment[source]
- Parameters:
i (int) – Index of sliding window position
- Returns:
segment – Sliding window at ith position
- Return type:
- __iter__() SlidingWindow[source]
Sliding window iterator
Use expression ‘for segment in sliding_window’
Examples
>>> window = SlidingWindow(end=0.1) >>> for segment in window: ... print(segment) [ 00:00:00.000 --> 00:00:00.030] [ 00:00:00.010 --> 00:00:00.040] [ 00:00:00.020 --> 00:00:00.050] [ 00:00:00.030 --> 00:00:00.060] [ 00:00:00.040 --> 00:00:00.070] [ 00:00:00.050 --> 00:00:00.080] [ 00:00:00.060 --> 00:00:00.090] [ 00:00:00.070 --> 00:00:00.100] [ 00:00:00.080 --> 00:00:00.110] [ 00:00:00.090 --> 00:00:00.120]
- __len__() int[source]
Number of positions
Equivalent to len([segment for segment in window])
- Returns:
length – Number of positions taken by the sliding window (from start times to end times)
- Return type:
int
- __weakref__
list of weak references to the object (if defined)
- closest_frame(t: float) int[source]
Closest frame to timestamp.
- Parameters:
t (float) – Timestamp, in seconds.
- Returns:
index – Index of frame whose middle is the closest to timestamp
- Return type:
int
- copy() SlidingWindow[source]
Duplicate sliding window
- crop(focus: Segment | Timeline, mode: Literal['center', 'loose', 'strict'] = 'loose', fixed: float | None = None, return_ranges: bool | None = False) ndarray | List[List[int]][source]
Crop sliding window
- Parameters:
focus (Segment or Timeline)
mode ({'strict', 'loose', 'center'}, optional) – In ‘strict’ mode, only indices of segments fully included in ‘focus’ support are returned. In ‘loose’ mode, indices of any intersecting segments are returned. In ‘center’ mode, first and last positions are chosen to be the positions whose centers are the closest to ‘focus’ start and end times. Defaults to ‘loose’.
fixed (float, optional) – Overrides Segment ‘focus’ duration and ensures that the number of returned frames is fixed (which might otherwise not be the case because of rounding erros).
return_ranges (bool, optional) – Return as list of ranges. Defaults to indices numpy array.
- Returns:
indices – Array of unique indices of matching segments
- Return type:
np.array (or list of ranges)
- property duration: float
Sliding window duration in seconds.
- property end: float
Sliding window end time in seconds.
- range_to_segment(i0: int, n: int) Segment[source]
Convert 0-indexed frame range to segment
Each frame represents a unique segment of duration ‘step’, centered on the middle of the frame.
The very first frame (i0 = 0) is the exception. It is extended to the sliding window start time.
- Parameters:
i0 (int) – Index of first frame
n (int) – Number of frames
- Returns:
segment
- Return type:
Examples
>>> window = SlidingWindow() >>> print window.range_to_segment(3, 2) [ --> ]
- samples(from_duration: float, mode: Literal['center', 'loose', 'strict'] = 'strict') int[source]
Number of frames
- Parameters:
from_duration (float) – Duration in seconds.
mode ({'strict', 'loose', 'center'}) – In ‘strict’ mode, computes the maximum number of consecutive frames that can be fitted into a segment with duration from_duration. In ‘loose’ mode, computes the maximum number of consecutive frames intersecting a segment with duration from_duration. In ‘center’ mode, computes the average number of consecutive frames where the first one is centered on the start time and the last one is centered on the end time of a segment with duration from_duration.
- segment_to_range(segment: Segment) Tuple[int, int][source]
Convert segment to 0-indexed frame range
- Parameters:
segment (Segment)
- Returns:
i0 (int) – Index of first frame
n (int) – Number of frames
Examples
>>> window = SlidingWindow() >>> print window.segment_to_range(Segment(10, 15)) i0, n
- property start: float
Sliding window start time in seconds.
- property step: float
Sliding window step in seconds.
SlidingWindowFeature
- class pyannote.core.SlidingWindowFeature(data: ndarray, sliding_window: SlidingWindow, labels: List[str] | None = None)[source]
Periodic feature vectors
- Parameters:
data ((n_frames, n_features) numpy array)
sliding_window (SlidingWindow)
labels (list, optional) – Textual description of each dimension.
- __init__(data: ndarray, sliding_window: SlidingWindow, labels: List[str] | None = None)[source]
- __weakref__
list of weak references to the object (if defined)
- align(to: SlidingWindowFeature) SlidingWindowFeature[source]
Align features by linear temporal interpolation
- Parameters:
to (SlidingWindowFeature) – Features to align with.
- Returns:
aligned – Aligned features
- Return type:
- crop(focus: Segment | Timeline, mode: Literal['center', 'loose', 'strict'] = 'loose', fixed: float | None = None, return_data: bool = True) ndarray | SlidingWindowFeature[source]
Extract frames
- Parameters:
mode ({'loose', 'strict', 'center'}, optional) – In ‘strict’ mode, only frames fully included in ‘focus’ support are returned. In ‘loose’ mode, any intersecting frames are returned. In ‘center’ mode, first and last frames are chosen to be the ones whose centers are the closest to ‘focus’ start and end times. Defaults to ‘loose’.
fixed (float, optional) – Overrides Segment ‘focus’ duration and ensures that the number of returned frames is fixed (which might otherwise not be the case because of rounding errors).
return_data (bool, optional) – Return a numpy array (default). For Segment ‘focus’, setting it to False will return a SlidingWindowFeature instance.
- Returns:
data – Frame features.
- Return type:
numpy.ndarray or SlidingWindowFeature
See also
- property dimension
Dimension of feature vectors
Visualization
Visualization
pyannote.core.Segment, pyannote.core.Timeline,
pyannote.core.Annotation and pyannote.core.SlidingWindowFeature
instances can be directly visualized in notebooks.
You will however need to install pyannote.core’s additional dependencies
for notebook representations (namely, matplotlib):
pip install pyannote.core[notebook]
Segments
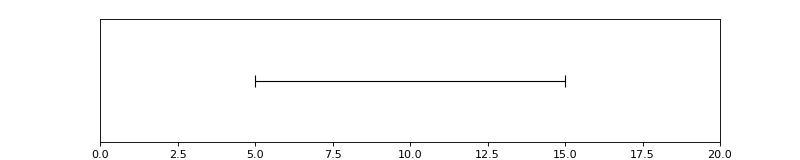
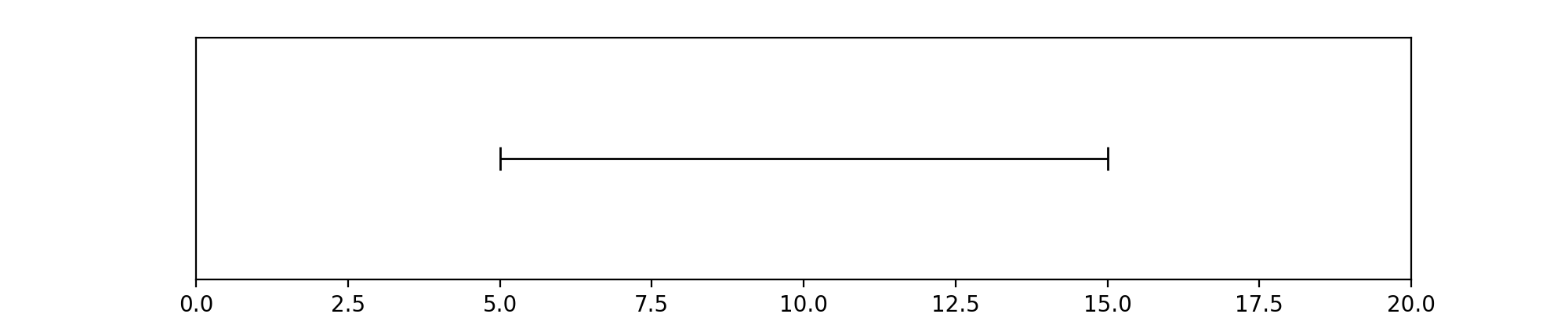
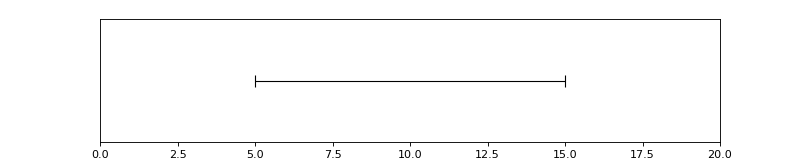
In [1]: from pyannote.core import Segment
In [2]: segment = Segment(start=5, end=15)
....: segment
(Source code, png, hires.png, pdf)
{kind=link}
{kind=link}
Timelines
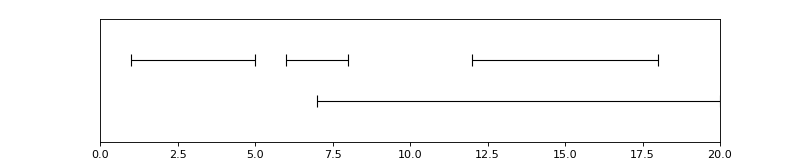
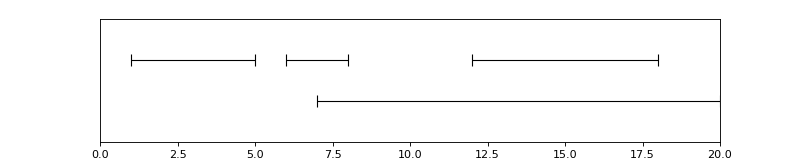
In [25]: from pyannote.core import Timeline, Segment
In [26]: timeline = Timeline()
....: timeline.add(Segment(1, 5))
....: timeline.add(Segment(6, 8))
....: timeline.add(Segment(12, 18))
....: timeline.add(Segment(7, 20))
....: timeline
(Source code, png, hires.png, pdf)
{kind=link}
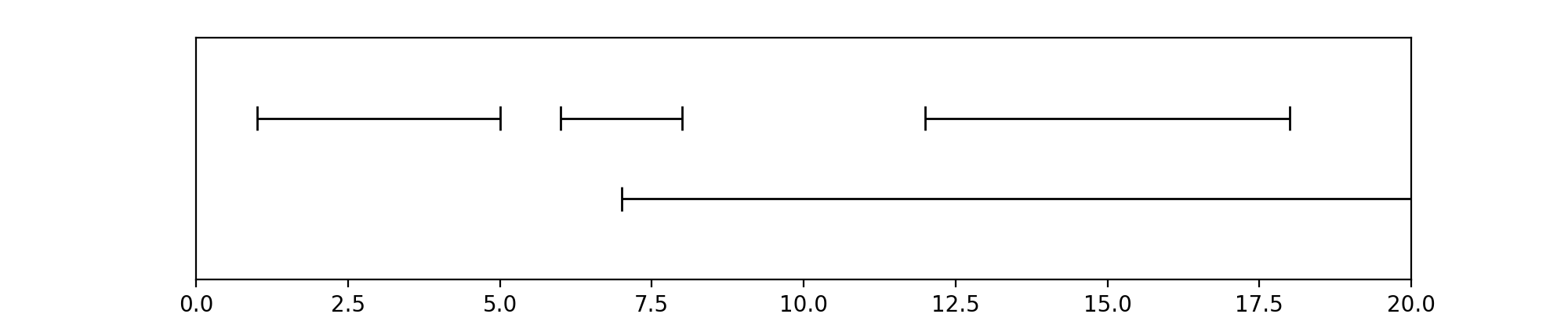{kind=link}
Annotations
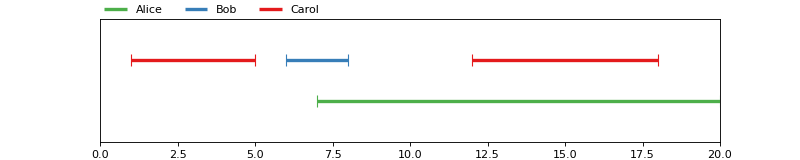
In [1]: from pyannote.core import Annotation, Segment
In [6]: annotation = Annotation()
...: annotation[Segment(1, 5)] = 'Carol'
...: annotation[Segment(6, 8)] = 'Bob'
...: annotation[Segment(12, 18)] = 'Carol'
...: annotation[Segment(7, 20)] = 'Alice'
...: annotation
(Source code, png, hires.png, pdf)
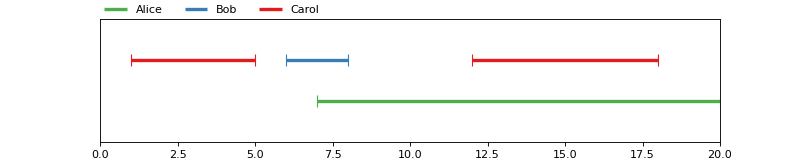{kind=link}
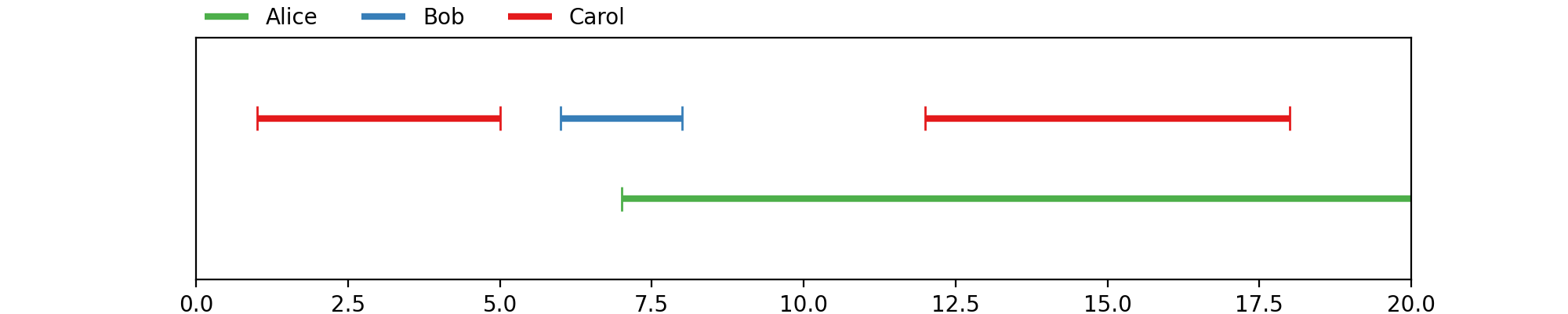{kind=link}
- pyannote.core.notebook.repr_annotation(annotation: Annotation)[source]
Get png data for annotation
- pyannote.core.notebook.repr_feature(feature: SlidingWindowFeature)[source]
Get png data for feature