Available data structures
Segment
(Source code, png, hires.png, pdf)
{kind=link}
{kind=link}
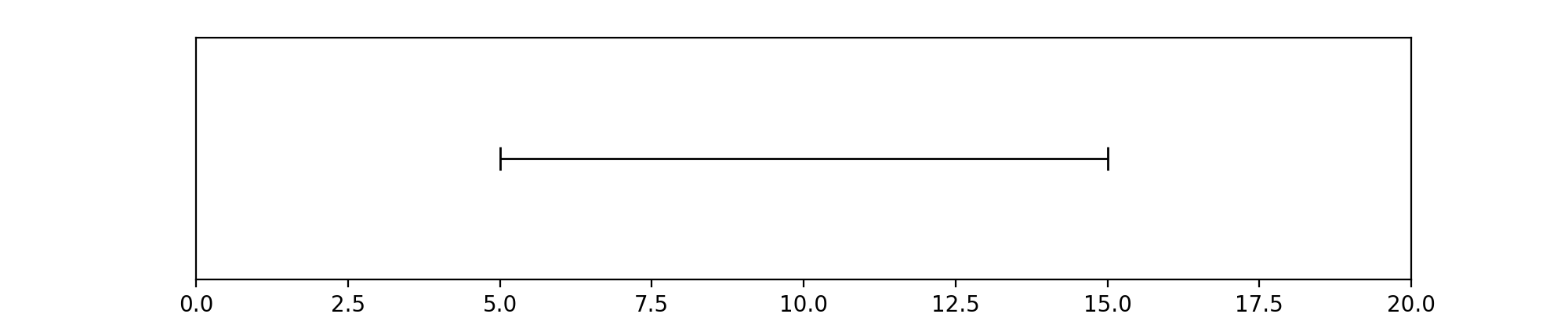
pyannote.core.Segment instances describe temporal fragments (e.g. of an audio file). The segment depicted above can be defined like that:
In [1]: from pyannote.core import Segment
In [2]: segment = Segment(start=5, end=15)
In [3]: print(segment)
It is nothing more than 2-tuples augmented with several useful methods and properties:
In [4]: start, end = segment
In [5]: start
In [6]: segment.end
In [7]: segment.duration # duration (read-only)
In [8]: segment.middle # middle (read-only)
In [9]: segment & Segment(3, 12) # intersection
In [10]: segment | Segment(3, 12) # union
In [11]: segment.overlaps(3) # does segment overlap time t=3?
Use Segment.set_precision(ndigits) to automatically round start and end timestamps to ndigits precision after the decimal point. To ensure consistency between Segment instances, it is recommended to call this method only once, right after importing pyannote.core.Segment.
In [12]: Segment(1/1000, 330/1000) == Segment(1/1000, 90/1000+240/1000)
Out[12]: False
In [13]: Segment.set_precision(ndigits=4)
In [14]: Segment(1/1000, 330/1000) == Segment(1/1000, 90/1000+240/1000)
Out[14]: True
See pyannote.core.Segment for the complete reference.
Timeline
(Source code, png, hires.png, pdf)
{kind=link}
{kind=link}
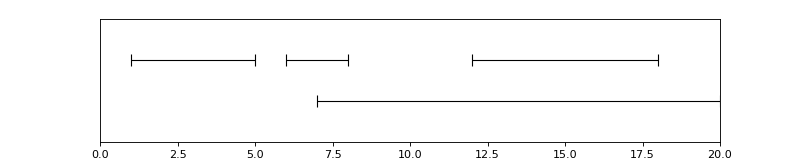
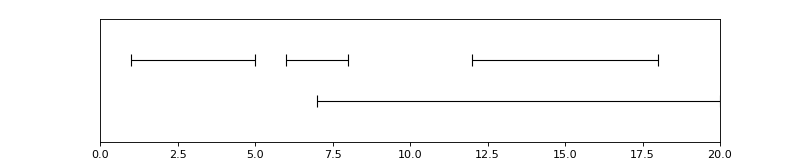
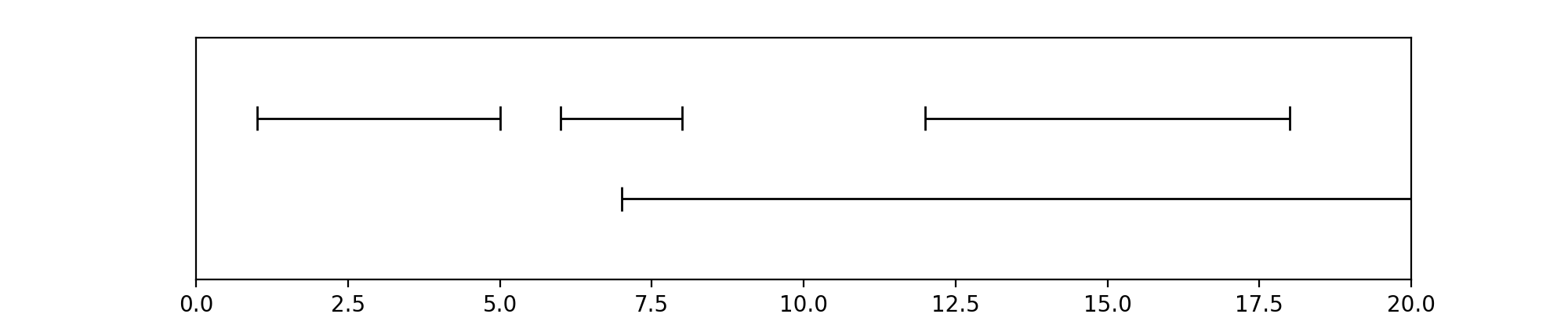
pyannote.core.Timeline instances are ordered sets of non-empty
segments:
ordered, because segments are sorted by start time (and end time in case of tie)
set, because one cannot add twice the same segment
non-empty, because one cannot add empty segments (i.e. start >= end)
There are two ways to define the timeline depicted above:
In [25]: from pyannote.core import Timeline, Segment
In [26]: timeline = Timeline()
....: timeline.add(Segment(1, 5))
....: timeline.add(Segment(6, 8))
....: timeline.add(Segment(12, 18))
....: timeline.add(Segment(7, 20))
....:
In [27]: segments = [Segment(1, 5), Segment(6, 8), Segment(12, 18), Segment(7, 20)]
....: timeline = Timeline(segments=segments, uri='my_audio_file') # faster
....:
In [9]: for segment in timeline:
...: print(segment)
...:
[ 00:00:01.000 --> 00:00:05.000]
[ 00:00:06.000 --> 00:00:08.000]
[ 00:00:07.000 --> 00:00:20.000]
[ 00:00:12.000 --> 00:00:18.000]
Note
The optional uri keyword argument can be used to remember which document it describes.
Several convenient methods are available. Here are a few examples:
In [3]: timeline.extent() # extent
Out[3]: <Segment(1, 20)>
In [5]: timeline.support() # support
Out[5]: <Timeline(uri=my_audio_file, segments=[<Segment(1, 5)>, <Segment(6, 20)>])>
In [6]: timeline.duration() # support duration
Out[6]: 18
See pyannote.core.Timeline for the complete reference.
Annotation
(Source code, png, hires.png, pdf)
{kind=link}
{kind=link}
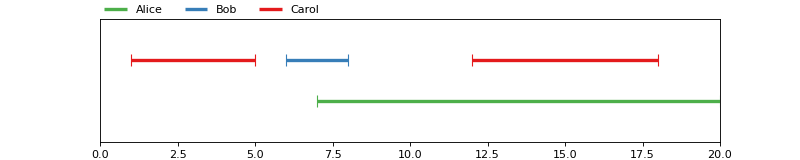
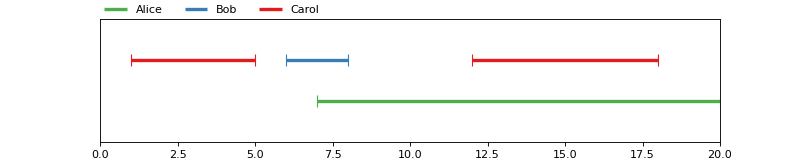
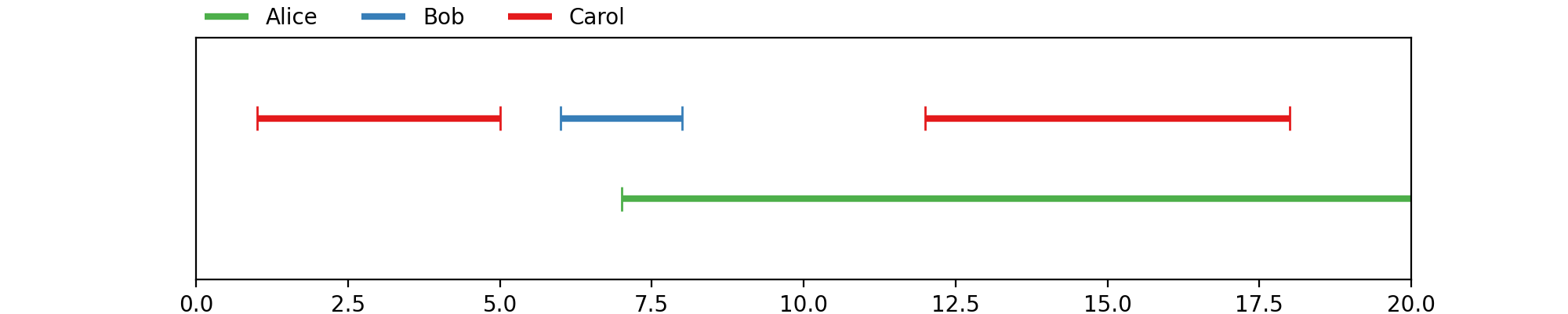
pyannote.core.Annotation instances are ordered sets of non-empty
tracks:
ordered, because segments are sorted by start time (and end time in case of tie)
set, because one cannot add twice the same track
non-empty, because one cannot add empty track
A track is a (support, name) pair where support is a Segment instance, and name is an additional identifier so that it is possible to add multiple tracks with the same support.
To define the annotation depicted above:
In [1]: from pyannote.core import Annotation, Segment
In [6]: annotation = Annotation()
...: annotation[Segment(1, 5)] = 'Carol'
...: annotation[Segment(6, 8)] = 'Bob'
...: annotation[Segment(12, 18)] = 'Carol'
...: annotation[Segment(7, 20)] = 'Alice'
...:
which is actually a shortcut for
In [6]: annotation = Annotation()
...: annotation[Segment(1, 5), '_'] = 'Carol'
...: annotation[Segment(6, 8), '_'] = 'Bob'
...: annotation[Segment(12, 18), '_'] = 'Carol'
...: annotation[Segment(7, 20), '_'] = 'Alice'
...:
where all tracks share the same (default) name '_'.
In case two tracks share the same support, use a different track name:
In [6]: annotation = Annotation(uri='my_video_file', modality='speaker')
...: annotation[Segment(1, 5), 1] = 'Carol' # track name = 1
...: annotation[Segment(1, 5), 2] = 'Bob' # track name = 2
...: annotation[Segment(12, 18)] = 'Carol'
...:
The track name does not have to be unique over the whole set of tracks.
Note
The optional uri and modality keywords argument can be used to remember which document and modality (e.g. speaker or face) it describes.
Several convenient methods are available. Here are a few examples:
In [9]: annotation.labels() # sorted list of labels
Out[9]: ['Bob', 'Carol']
In [10]: annotation.chart() # label duration chart
Out[10]: [('Carol', 10), ('Bob', 4)]
In [11]: list(annotation.itertracks())
Out[11]: [(<Segment(1, 5)>, 1), (<Segment(1, 5)>, 2), (<Segment(12, 18)>, u'_')]
In [12]: annotation.label_timeline('Carol')
Out[12]: <Timeline(uri=my_video_file, segments=[<Segment(1, 5)>, <Segment(12, 18)>])>
See pyannote.core.Annotation for the complete reference.
Features
See pyannote.core.SlidingWindowFeature for the complete reference.